Twice the Bits, Twice the Trouble: Vulnerabilities Induced by Migrating to 64-Bit Platforms 번역 및 요약
0. 서론
- 어떤 플랫폼에서 안전하다고 판단된 코드라도 다른 플랫폼에서는 취약할 수 있으므로 코드의 마이그레이션은 취약점이 발생될 수 있다.
- 해당 논문에서는 32bit에서 예상대로 동작하는 코드가 64bit에서 어떻게 취약해질 수 있는지에 대한 연구를 제공한다.
- 정수 자료형의 폭이 넓어지고 주소를 지정할 수 있는 메모리의 양이 늘어남에 따라 이전에는 존재하지 않았던 취약점이 프로그램 코드에 숨어 있는 것을 알아냈다.
- Debian stable 및 Github에서 인기 있는 200개 오픈소스를 대상으로 경험적 연구를 통해 확인하였다.
- 또한 Chromium, Boost C++ Libraries, libarchive, Linux Kernel, zlib을 포함하여 연구를 통해 발견된 64bit 마이그레이션 취약점에 대해 설명한다.
1. 소개
- 64bit 아키텍쳐는 서버, 데스크톱의 기본 플랫폼이 되었으며 Linux, Windows, OSX 등 모든 주요 운영체제는 64bit 아키텍쳐를 지원하도록 포팅되었다.
- 64bit 아키텍쳐에서 실행되는 프로그램은 큰 주소공간을 사용할 수 있다는 이점이 있다.
- 64bit로의 마이그레이션은 보기에는 간단해 보일지라도 버그를 유발할 수 있으므로 훨씬 복잡하다.
- 해당 논문에서는 64bit 데이터 모델을 분석하여 마이그레이션 과정에서 발생하는 취약점에 대해 연구한다.
- 연구원들이 분석한 바에 따르면 마이그레이션 취약점은 해결하기 어렵다고 한다.
아래는 zlib에서 실제로 존재했던 간단한 취약점의 예시이다.
1
2
3
int len = attacker_controlled(); // 공격자가 제어하는 값을 읽고 x에 저장, x = 0xffffffff(-1) 라고 가정
char *buffer = malloc((unsigned) len); // len이 unsigned int(4byte)형으로 캐스팅 되므로 0xffffffff(4294967295)바이트 할당
memcpy(buffer, src, len); //len은 size_t(8byte)로 캐스팅 되며 부호 확장으로 인해 0xffffffffffffffff(9223372036854775807)이 되므로 overflow 발생
2. SECURITY OF INTEGER TYPES
- 정수가 메모리 버퍼 크기 또는 메모리 위치를 결정할 때 발생하는 결함에 취약점이 존재할 수 있다.
- 공격자는 위와 같은 결함을 이용하여 BOF를 유발하거나 AAR/AAW를 진행할 수 있다.
- 아래에서는 C/C++의 정수의 보안에 대한 배경 지식을 설명한다.
2.1 C언어에서의 정수 자료형
- 타입 캐스팅은 64비트 아키텍처로 포팅될 때 발생하는 취약점의 기반이 된다.
- C언어는 아래의 자료형을 표준으로 정의하였다.
char,short,int,long,long long
- 정수 자료형은 양수만을 저장하는 unsigned형과 음수도 포함하는 signed형이 존재한다.
- 아래는 C언어에 지정된 각각의 자료형에 대한 변환 순위이다.
char<short<int<long<long long- 순위가 낮은 자료형은 순위가 높은 자료형으로 캐스팅 된다.
2.2 데이터 모델
- 데이터 모델은 특정 플랫폼에 대한 정수 자료형의 크기를 말한다.
아래 표는 현재까지 사용된 데이터 모델에 대한 자료형의 정보이다.
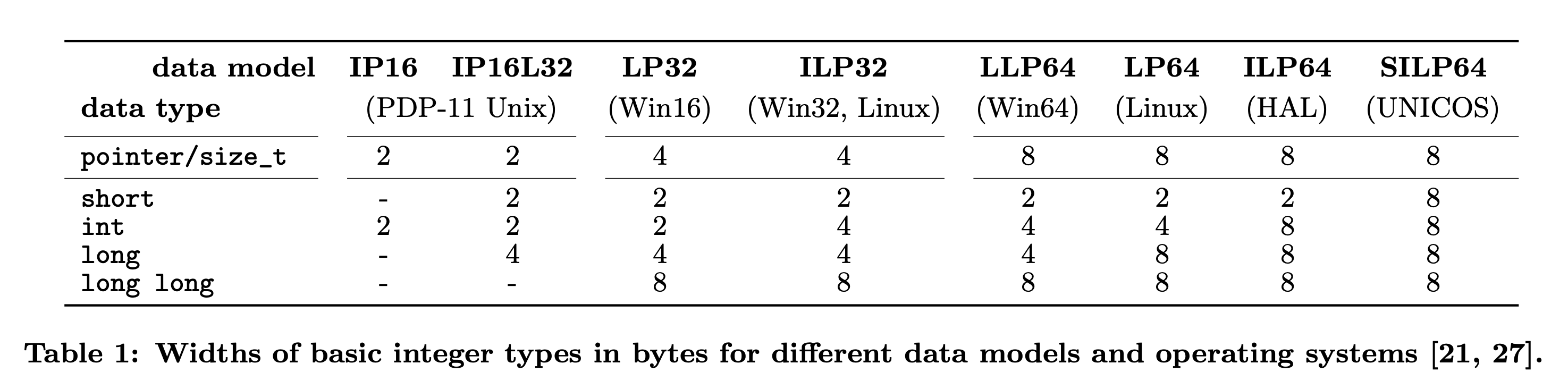
- 모든 모델에서 포인터와 size_t 자료형은 아키텍쳐의 레지스터 크기와 항상 동일하다.
- 32bit의 경우 int 자료형의 크기가 포인터와 동일하지만 64bit에서 int 자료형은 포인터의 절반이다.
- LLP64 데이터 모델의 long 자료형의 경우에도 동일하다.
- ILP64, SILP64의 경우에는 int와 포인터의 크기가 동일하지만 소수의 플랫폼에서만 사용된다.
2.3 정수 관련 취약점
- 몇몇 취약점은 버퍼의 크기, 메모리 오프셋, 메모리를 복사할 양을 계산하기 위해 정수를 처리하면서 발생하는 버그에 의해 발생된다.
- 위와 같은 정수 관련 취약점은 다음과 같은 공통 소스를 가진다.
- truncations - 정수 잘림
- undeflows/overflows - 언더플로/오버플로
- signedness issues - 부호 문제
아래에서는 32bit, 64bit 에서의 각 결함을 설명한다.
2.3.1 Integer Truncations - 정수 잘림
예를 들어 임의의 할당 코드x = e가 있을 때
x = ex: int (32bit)e: long (64bit)
할당을 받는 변수 x의 크기는 저장하도록 요청된 변수 e의 크기보다 작으므로 정수 잘림이 발생한다.
- 정수의 순위나 부호 잘림 발생 여부는 알려주지 않는다.
- 정수 잘림의 존재 여부는 정수의 크기, 즉 데이터 모델에 의존한다.
x의 크기가e보다 작을 수 있는 경우는x의 순위가e보다 낮을 때 뿐이므로 정수 잘림을 찾아낼 때 여기에 초점을 맞출 수 있다.- 예를 들어
e가 함수 매개 변수 또는 조건에 사용되는 경우x는 코드 상에서는 볼 수 없는 암시적 변수일 수 있다는 점에 유의해야 한다.
- 예를 들어
아래 코드는 BOF를 유발하는 정수 잘림의 예시이다.
1
2
3
4
unsigned int x = attacker_controlled(); // 공격자가 제어하는 값을 읽고 x에 저장, x = 0xffffffff 라고 가정
unsigned short y = x; // y의 크기는 x의 크기보다 작으므로 정수 잘림 발생
char *buffer = malloc(y); // 0xffff 바이트 할당
memcpy(buffer, src, x); // 할당된 버퍼의 크기보다 x의 값이 더 크므로 overflow 발생
2.3.2 Integer Overflows - 정수 오버플로
예를 들어 임의의 식 e1 ◦ e2가 있을 때
e1: int (32bit)e2: int (32bit)
e1 ◦ e2의 연산 결과가 int (32bit)에 속하지 않으면 정수 overflow 또는 underflow가 발생한다.
- oveflow의 존재 여부는 산술 연산 뿐만이 아닌 하위 표현식
e1 ◦ e2를 계산하여 얻은 모든 결과에 의존한다.
아래 코드는 BOF를 유발하는 정수 overflow의 예시이다.
1
2
3
unsigned int x = attacker_controlled(); // 공격자가 제어하는 값을 읽고 x에 저장, x = 0xffffffff 라고 가정
char *buffer = malloc(x + CONST); // x + 상수 값이 정수 최대값 보다 클 경우 integer overflow 발생, CONST가 0x100일 경우 버퍼는 0xff 크기를 가짐
memcpy(buffer, src, x); // 할당된 버퍼의 크기보다 x의 값이 더 크므로 overflow 발생
2.3.3 Integer Signedness Issues - 정수 부호 문제
예를 들어 임의의 할당 코드x = e가 있을 때
x = ex: int (32bit) or long (64bit), 양수e: int (32bit), 음수
x와 e의 부호가 서로 다르고, x의 크기가 e보다 같거나 크다면 부호 문제가 발생한다.
- 부호 문제는 주로
e의 부호에 따라 달라지지만 부호 있는x가 부호 없는e의 모든 값을 저장할 수 있는지에 따라서도 달라진다. x가e보다 작을 경우에는 정수 잘림이 발생한다.e가 부호 있는 자료형(signed)이고,x의 크기가e보다 클 경우 부호 확장이 발생한다. 즉, 크기가 작은 변수의 MSB가 크기가 큰 변수만큼 채워진다.- 예:
x = ex: int (32bit)e: short (16bit)e가 0xf000일 경우 →x= 0xfffff000
- 예:
아래 코드는 BOF를 유발하는 부호 확장 및 부호 변경의 예시이다.
1
2
3
short x = attacker_controlled(); // 공격자가 제어하는 값을 읽고 x에 저장, x = 0xffff(-1) 라고 가정
char *buffer = malloc((unsigned short) x); // unsigned short 형으로 변환되어 할당, 즉 양수로 변환됨
memcpy(buffer, src, x); // memcpy 내부의 타입 캐스팅으로 인해 x가 size_t 형으로 변환, 즉 x는 부호 확장으로 인해 0xffffffff(4294967295)으로 변환되므로 overflow 발생
해당 논문에서는 일반적인 유형의 취약점 외에도 다른 정수 결함을 고려한다.
예를 들어 두 표현식 e1, e2의 비교에서 부호 있는 자료형(signed)에서 부호 없는 자료형(unsigned)으로 변환될 경우 정수 부호 문제가 발생한다.
1
2
- 반대의 경우도 마찬가지이다.
- 이러한 종류의 정수 부호 문제는 비교되는 자료형의 부호, 순위, 너비에 따라 달라진다.
아래 코드는 부호가 서로 다른 변수를 비교하여 BOF를 유발하는 예시이다.
1
2
3
4
5
int x = attacker_controlled(); // 공격자가 제어하는 값을 읽고 x에 저장, x = 0xffffffff(-1) 라고 가정
unsigned short BUF_SIZE = 10; // 위의 변수와 다른 자료형을 가지는 변수 BUF_SIZE
if (x >= BUF_SIZE) // BOF를 방지하기 위한 코드, 서로 다른 부호를 가진 변수를 비교하므로 해당 조건을 우회할 수 있음. BUF_SIZE가 부호 있는 자료형(signed)으로 변환된다. -> (-1 > 10) == FALSE
return;
memcpy(buffer, src, x); // x가 size_t로 변환되므로 양수(4294967295)로 변환되어 overflow 발생
3. 64bit 마이그레이션 취약점
- 정수 관련 취약점은 이전에 자세하게 연구되어 분석, 감지, 패치를 위한 여러 방법이 제안되었다.
- 그러나 이러한 취약점들은 잘못된 타입 캐스팅 같이 개발자의 실수로 인해 발생하는 취약점들이다.
- 이 논문에서는 64bit로 마이그레이션함으로써 기존의 데이터 모델에는 존재하지 않는 취약점을 연구한다.
- 마이그레이션 취약점은 간접적으로 발생하므로 개발자가 이후의 마이그레이션을 예상하지 않고서는 발견하기 어렵다.
아래의 내용들은 32bit 플랫폼에서는 안전하지만 64bit 플랫폼에서 발생하는 다양한 취약점을 설명한다.
위와 같은 취약점은 두가지로 분류할 수 있다.
- changes in the width of integers - 정수의 크기 변경
- the larger address space available on 64-bit systems - 64bit 시스템에서 사용 가능한 더 큰 주소 공간
3.1 Effects of Integer Width Changes - 정수 크기 변화의 영향
- 32bit 플랫폼에서 사용 가능한 모든 정수형 타입은 64bit에도 존재하지만 두 타입 크기는 다를 수도 있다.
- 이러한 변경은 이전에는 존재하지 않던 정수 잘림이나 부호 확장 같은 취약점을 발생시킬 수 있다.
3.1.1 New Truncations
2.3 정수 관련 취약점에서 설명했던 것처럼 표현식이 자신의 타입보다 더 작은 타입에 할당될 때 정수 잘림이 발생한다.
아래 그림은 할당으로 인해 발생하는 정수 관련 문제에 대한 기본적인 정수 자료형에 대한 설명이다.

- 왼쪽부터 ILP32, LLP64, LP64 순서이다.
- 흰색 원 : 문제 없음
- 회색 원 : 부호 변경 가능
- (E) : 부호 확장
- 검정색 원 : 정수 잘림
size_t → unsigned int 또는 long → int 와 같은 변환은 32bit 플랫폼과 64bit 플랫폼이 다르게 동작한다.
또한 간단한 정수 잘림 취약점 외에도 데이터 모델의 마이그레이션은 포인터 처리와 관련된 다음 두가지 취약점을 가질 수 있다.
- Incorrect pointer differences
- Casting pointers to integers
Incorrect pointer differences
문자열 길이 같은 메모리 영역의 길이는 포인터 - 포인터를 통해 포인터와 같은 크기를 가진 ptrdiff_t 타입으로 저장할수 있다.
그러나 int 타입에 저장하는 것이 일반적이며 아래와 같은 문제가 발생한다.
- 32bit : int와 ptrdiff_t의 크기가 동일하기 때문에 문제가 발생하지 않는다.
- 64bit : ptrdiff(8byte) > int(4byte) 이므로 정수 잘림이 발생한다.
아래 코드는 Incorrect pointer differences에 의해 BOF를 유발하는 예시이다.
1
2
3
4
5
6
7
8
char buf[MAX_LINE_SIZE];
char *eol = strchr(str, '\n'); // str 문자열에서 \n 문자의 위치를 포인터 변수 eol에 대입
*eol = '\0'; // 문자 치환 \n -> \0
unsigned int len = eol - str; // 포인터 - 포인터 연산으로 문자열 길이를 구함. 결과로 나오는 값의 자료형이 8byte인 것에 비해 unsigned int(4byte)형으로 길이를 저장하므로 포인터 절단이 발생
if (len >= MAX_LINE_SIZE) // 정수형 절단으로 인해 해당 조건을 우회할 수 있음
return -1;
strcpy(buf, str); // overflow 발생
Casting pointers to integers
- 포인터에서 정수로 타입 캐스팅
- 32bit 플랫폼에서는 포인터와 정수 자료형의 크기가 동일하므로 문제가 되지 않는다.
- 64bit 플랫폼에서는 포인터가 정수 자료형보다 크므로 포인터 절단이 발생될 수 있다.
- 잘림이 발생하더라도 포인터가 주소 공간의 첫 4gb의 위치를 가리키기 때문에 잠재적인 상태이다.
- 이는 공격자가 안전한 범위 밖에 포인터가 할당되도록 메모리 할당량을 의도적으로 늘림으로써 해결할 수 있지만 ASLR에 의해 악용이 어렵다.
아래 코드는 Casting pointers to integers로 인해 정수 잘림이 발생하는 예시이다.
1
2
3
4
5
6
7
8
int origin;
int x = &origin; // casting pointer to integer
printf("origin ptr's size : %d\n", sizeof(&origin));
printf("x's size : %d\n", sizeof(x));
printf("origin : 0x%lx\n", &origin);
printf("x : 0x%lx\n", x);
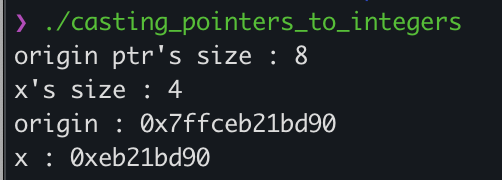
3.1.2 New Signedness Issues
32bit에서 64bit로 포팅될 때 두가지의 정수 부호 이슈가 발생된다.
- Sign extension - signed int형이 32bit보다 큰 unsigned형으로 변환될 때 부호 확장이 발생
- Signedness of comparisons - 비교 구문에서 부호가 변경되어 BOF를 방어하기 위한 검사를 우회
Sign extension - 부호 확장
- 하나의 signed형을 더 큰 signed형으로 변환한다면, 값 보존을 위해 부호 확장이 수행된다.
- 변환하고자 하는 자료형이 unsigned형 이어도 동일하게 부호 확장을 수행하지만 결과값은 unsigned형으로 해석된다.
- 이러한 과정에서 음수는 매우 큰 양수로 변환되므로 취약점이 될 수 있다.
아래 두가지 데이터 모델의 경우 다음과 같은 변환에서 부호 확장이 발생한다.
- LLP64
- int 또는 long → size_t
- LP64
- int → unsigned long 또는 size_t
size_t로의 타입 캐스팅은 취약점이 존재할 확률이 높다.
1. 소개에서 해당 문제에 대해 설명한다.
Signedness of comparisons - 비교 구문에서의 부호
- BOF를 막는 검사는 올바르게 계산하는 경우에만 유효하다.
- 이는 정수를 비교하기 전에 unsigned형으로 변환해야 함을 의미한다.
- 대부분의 경우 정수 변환 규칙에 따라 unsigned형으로 비교가 수행된다.
- 64bit 플랫폼의 경우 비교 구문에서 타입캐스팅이 일어날 때 부호가 변경되는 문제가 발생된다.
아래 그림은 각 정수 자료형의 부호 비교에 대한 설명이다.
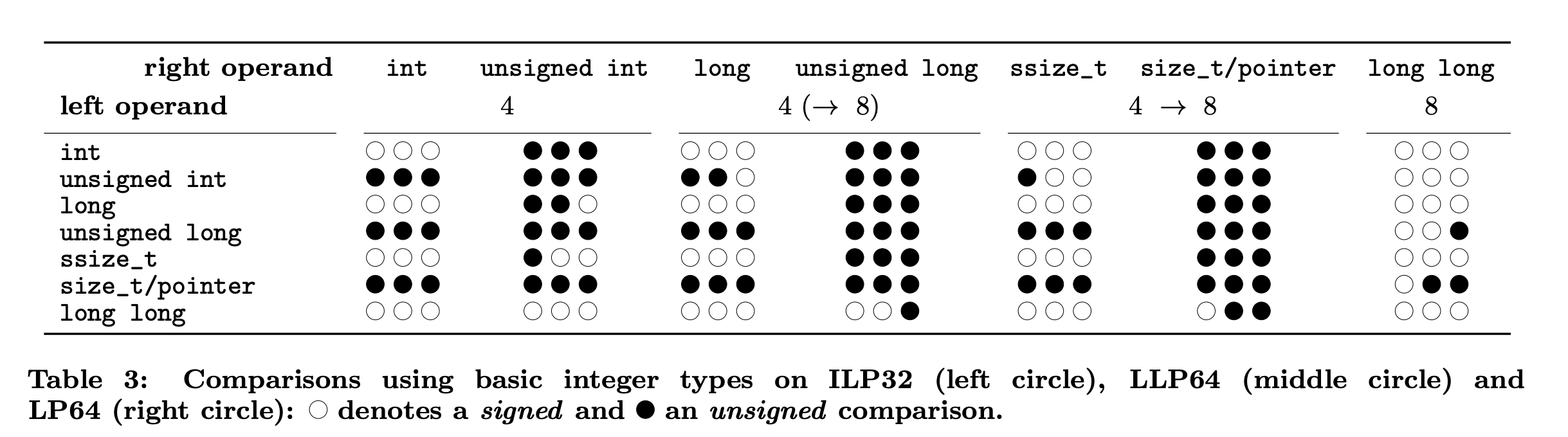
- 왼쪽부터 ILP32, LLP64, LP64 순서이다.
- 흰색 원 : 부호를 포함한 비교
- 검정색 원 : 부호를 포함하지 않은 비교
아래 코드는 LP64에서 부호를 포함하는 비교를 수행하면서 BOF가 발생하는 예시이다.
1
2
3
4
5
6
const unsigned int BUF_SIZE = 128; // 부호 없는 4byte 정수
long len = attacker_controlled(); // 공격자가 제어하는 값을 읽고 len(8byte)에 저장, len = 0xffffffffffffffff(-1) 라고 가정하며 부호가 존재함
if(len > BUF_SIZE) // long형은 unsigned int형보다 크므로 규칙에 의해 부호 있는 비교가 수행되며 조건 우회 가능. 위의 표 참조
return;
memcpy(buffer, src, len); // long형은 size_t형으로 캐스팅 되므로 부호 없는 정수(9223372036854775807)로 해석되면서 overflow 발생
위 코드는 32bit 플랫폼에서 아무런 문제가 발생하지 않는다.
3.2 Effects of a Larger Address Space - 더 큰 주소 공간의 영향
64bit 플랫폼은 주소 공간의 크기가 기존 4GB에서 수백TB로 증가했기 때문에 프로그램은 더 큰 양의 메모리를 처리할 수 있어야 한다.
- 이는 정수 잘림, 정수 오버플로가 추가적으로 발생할 수 있음을 뜻한다.
3.2.1 Dormant Integer Overflows
- 정수 오버플로는 변수의 자료형의 추측만으로는 찾을 수 없으므로 변수가 가질 수 있는 값의 범위도 고려해야 한다.
- 주소 공간이 크다는 뜻은 더 큰 개체를 만들고 더 많은 개체를 사용할 수 있음을 말한다.
- 포인터보다 작은 자료형(예: 4byte)으로 크기 또는 객체 수에 대한 연산을 수행하는 코드는 64bit에서 정수 오버플로에 취약하다.
1
2
3
4
5
6
7
unsigned int i; // 부호 없는 4byte 저장
size_t len = attacker_controlled(); // 공격자가 제어하는 값을 읽고 len(8byte)에 저장, i보다 큰 값을 가질 수 있음. len = 0x0000000100000000 라고 가정
char *buf = malloc(len);
for(i = 0; i < len; i++) { // len이 i보다 큰 값을 가질 수 있으므로 UINT_MAX 보다 큰 값을 가질 경우 i는 영원히 len에 도달할 수 없음(i는 정수 오버플로가 발생됨). 즉, 무한 루프 발생
*buf++ = get_next_byte(); // 할당된 영역보다 더 많은 영역을 읽을 수 있으므로 overflow 발생
}
위 코드는 32bit 플랫폼에서 아무런 문제가 발생하지 않는다.
3.2.2 Dormant Signedness Issues
- 부호 문제는 주소 공간의 크기가 커짐에 따라 악용될 수 있다.
- 예 : strlen의 반환 값(8byte)을 int형(4byte)에 할당할 경우
- 문자열의 길이가 INT_MAX의 길이보다 클 경우 음수가 된다.
- 예 : strlen의 반환 값(8byte)을 int형(4byte)에 할당할 경우
1
2
3
4
5
6
char buffer[128];
int len = strlen(attacker_str); // 공격자가 제어하는 값의 길이를 len(4byte)에 저장, strlen은 8byte를 반환하므로 len을 음수로 만들 수 있으며 나머지 4byte는 버려짐. strlen의 반환 값 = 0x00000000ffffffff(4294967295), len = 0xffffffff(-1) 라고 가정
if(len >= 128) // 위의 잘못된 자료형으로 인해 len = -1 이므로 해당 조건을 우회할 수 있음
return;
memcpy(buffer, attacker_str , len); // int형(4byte)이 size_t형(8byte)으로 타입캐스팅 되면서 부호 확장 발생 및 unsigned형으로 변환됨. 즉, len = 9223372036854775807이 되므로 overflow 발생
3.2.3 Unexpected Behavior of Library Functions
- 몇몇의 C 표준 라이브러리 함수는 32bit 데이터모델을 기반으로 설계했기 때문에 위에서 말한 버그들에 대해 취약하다.
- 이 중 일부는 64bit에 맞게 수정되었지만 해당 함수를 사용하는 개발자는 변경된 기능을 인식하지 못하는 경우가 많다.
String formatting
fprintf, snprintf, vsnprintf 와 같은 문자열 출력 함수는 인자로 전달되는 문자열이 INT_MAX 보다 클 수 없다는 가정하에 설계되었다.
- 이는 64bit 플랫폼에는 적용되지 않는다.
아래 코드는 snprintf를 사용하는 예시이다.
1
int snprintf(char *s, size_t n, const char *fmt, ...)
- 위 함수는 n 바이트를 복사하며, 복사된 바이트 수를 반환한다.
- 64bit 플랫폼에서는 문자열의 길이가 INT_MAX 보다 클 수 있으므로 반환되는 데이터가 snprintf의 반환 자료형인 int를 초과할 수 있다.
- 해당 경우에 대해 C99 표준은 -1을 반환하도록 정의하였다.
1
2
3
4
5
6
if (__glibc_unlikely (width >= INT_MAX / sizeof (CHAR_T) - EXTSIZ))
{
__set_errno (EOVERFLOW);
done = -1;
goto all_done;
}
아래 코드는 snrprintf를 잘못 사용하여 Stack Corruption이 발생하는 예시이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
int pos = 0;
char buf[BUF_LEN + 1];
int log(char *str)
{
int n = snprintf(buf + pos, BUF_LEN - pos, "%s", str); // str의 길이가 INT_MAX 보다 큰 문자열이라고 가정. 두번째 인자에 전달된 사이즈에 관계 없이 snprintf는 -1을 반환함. 즉 n = -1
if (n > BUF_LEN - pos) // n = -1 이므로 해당 조건식을 우회할 수 있음
{
pos = BUF_LEN;
return -1;
}
return (pos += n); // 최종적으로 pos = -1이 되며 이후 로직에서 log 함수를 사용할 경우 oob가 발생될 수 있음
}
File processing
ftell, fseek, fgetpos와 같은 파일을 처리하는 C 표준 라이브러리 함수는 printf 계열 함수와 마찬가지로 64bit 정수의 영향을 받지 않도록 디자인 되었다.
- 32bit가 넘는 사이즈를 가진 데이터를 처리하고자 할 경우는 64bit 플랫폼을 위한 함수인
ftello,ftello64,__ftelli64함수로 해결할수 있다.- 경험적 연구에 따르면 여전히
ftell함수가 많이 사용된다고 한다.
- 경험적 연구에 따르면 여전히
ftell함수는 대용량 파일을 만날 경우 파일 포인터의 현재 위치를 long형으로 반환한다.- LLP64 데이터 모델을 사용하는 경우 32bit로 반환된다.
- Microsoft Visual C++ 런타임 라이브러리에서의
ftell함수 구현은 파일에서의 현재의 위치가 LONG_MAX를 초과하면 0을 반환한다.
아래 코드는 Microsoft Windows 64bit 플랫폼에서 잘못된 ftell 사용으로 인해 heap BOF가 발생하는 예시이다.
1
2
3
4
5
6
7
8
9
10
11
12
int i;
char *buf;
FILE *const f = fopen(filename, "r");
fseek(f, 0, SEEK_END); // 파일의 끝 위치로 이동
const long size = ftell(f); // 파일의 총 길이를 저장. 해당 파일이 LONG_MAX를 넘는 크기를 가졌을 경우 size = 0이 된다
buf = malloc(size / 2 + 1); // (0 / 2) + 1 = 1이므로 1byte 할당
fseek(f, 0, SEEK_SET); // 파일의 시작 위치로 이동
for (; fscanf(f, "%02x", &i) != EOF; buf++) // 파일의 끝을 만날 때까지 buf에 파일 내용을 넣음. 여기서 buf는 실제 파일 사이즈보다 작으므로 할당된 bound를 넘어서 값을 쓸 수 있음. 즉, overflow 발생
*buf = i;